
#4 Linux filesystem benchmark 2008/2
One might ask why yet another file-system benchmark article, and nothing more interesting in the few T2 magazine articles this year. Well, for one thing I just exchanged the too filled 120GB hard-disk of my MacBook Pro with a 320GB one (I already had to wipe huge VM images on a weekly to daily basis depending which customer I worked for!) and asked myself which filesystem to use on the new, free space.
The last benchmark was run on a dual-core G5, which probably triggered some not so clean code path in Reiser4 during the last test and thus reiser4 was absent in the first benchmark article. Additionally Ext4 is said to be "ready", now and BTRFS should have matured a little more.
Additionally I just came across a "Real World" benchmark at Phoronix and was wondering about the absense of JFS, Reiser4 and BTRFS.
The hardware
This time it was a MacBook Pro with a Intel Core2 Duo T7500 @ 2.20GHz, 2GB of RAM and 320GB 2.5" Western Digital WD3200BEKT-2 (Scorpio Black) @ 7200 RPM and 16MB cache and a SATA interface.
The Linux kernel was 2.6.27.8 on an mostly up-to-date T2 SDE 8.0-trunk (2008/03/17) with gcc-4.2.1.
Prologue
After the first article some people asked me per e-mail why I would benchmark so "not so real world many files and directories" performance patterns. The answer is simple: I often work with huge sets of data and need thousands of files accessed quickly. Some suggested to change this, however this requires extra complexity in my development and research applications (or T2 SDE compilations for that matter) and I rather spent my time doing interesting stuff than to work around fundamentally slow file-systems.
This access patterns also often expose bottle necks in serialization points and lookup algorithms.
In contrast to the last article this time I left out the HFS+ file-system I just benchmarked for the fun of it, in exchange for reiser4 and a tuned variant of XFS in the hope it would speed up:
Which is supposted to enable lazy counting and more allocation groups than the default.
The results
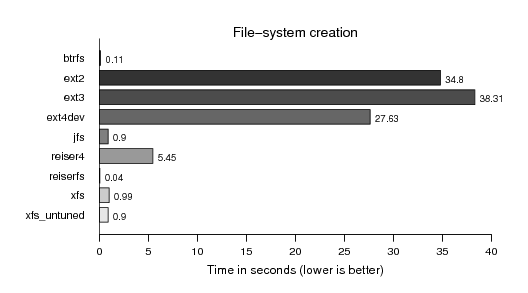
First comes the file system creation. Not of particular interest for me, only included because others do, too:
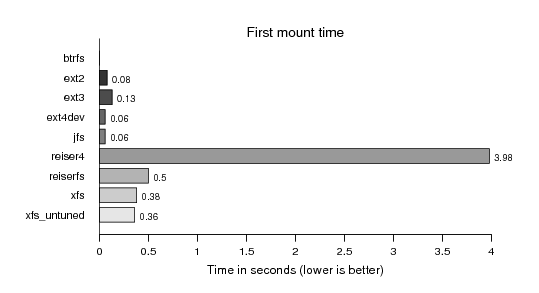
Same applies for the first mount time:
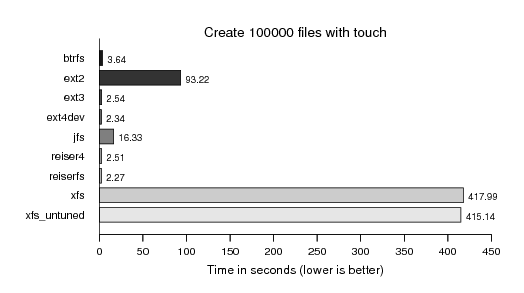
Creating 100000 files with a single invocation of touch, apparently not favoured by Ext2 and Ext4:
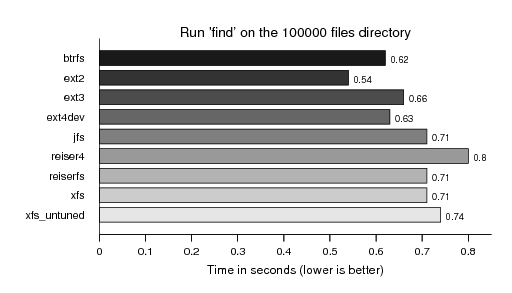
Run find on the directory with 100000 files. Mostly only included due the the Linux Gazetta article, particularly not that interesting as mostly in the sub-second domain, but this time better scaled as hfs+ is no longer stretching the graph:
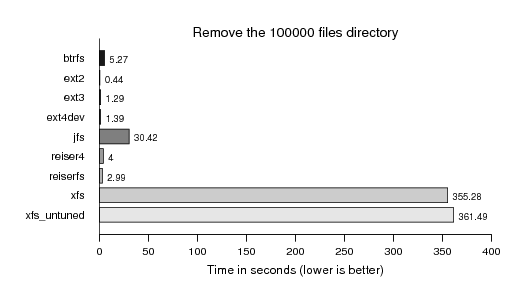
Next comes removing (rm -rf) the directory with 100000 files. As we see XFS is still particularly slow, and the attempt to tune it only helped partially::
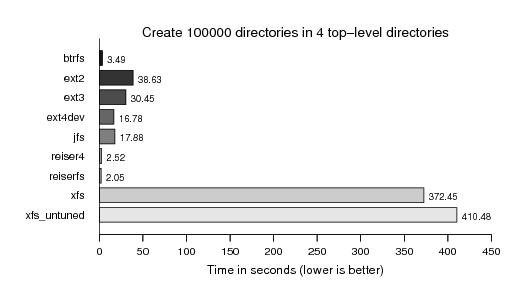
Now we continue the same game with directories. First the creation:
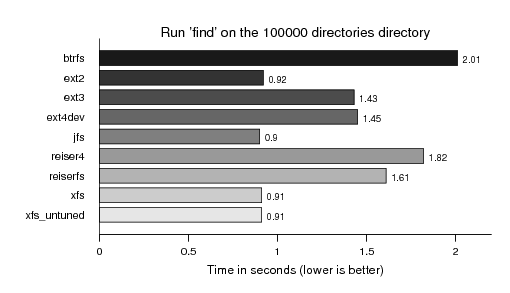
Running find on them:
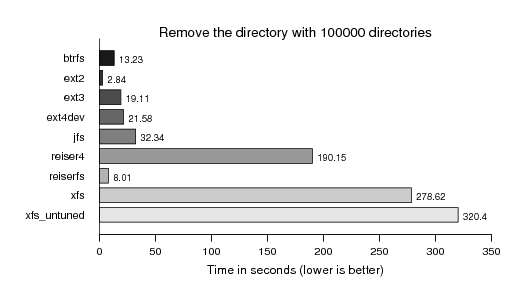
And last but not least removing them. Aside XFS Reiser4 is also not performing too well here:
Now we put some more payload into a huge collection of files in a single directory - 48k of zeros (from /dev/zero of course). Actually I found this particular payload while searching the internet for people's experience with filesystems and this particular load from someone complaining about XFS unlink (remove) performance. Actually a load where filesystems also differ a little more and BTRFS does still as bad as it did earlier this year:
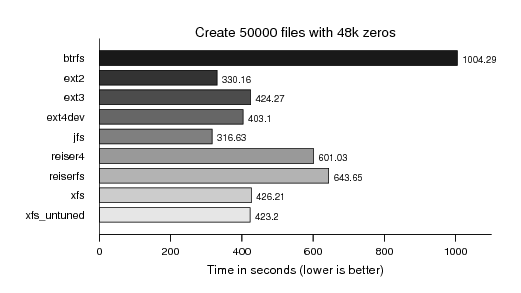
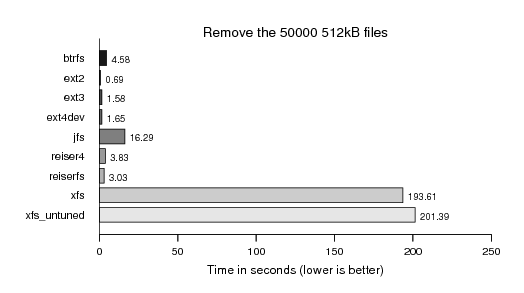
In particular XFS showing the known remove performance pattern:
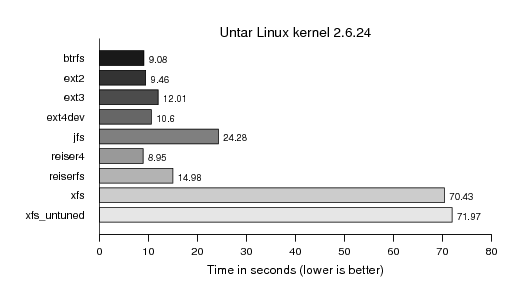
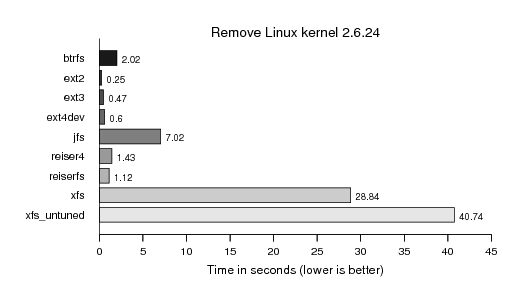
After the basic functionality tests we put some more developer's i/o pattern to the filesystem. Starting with extracting the currently latest 2.6 (.24) Linux kernel. I did not imagine such a divergence of the filesystems in this test:
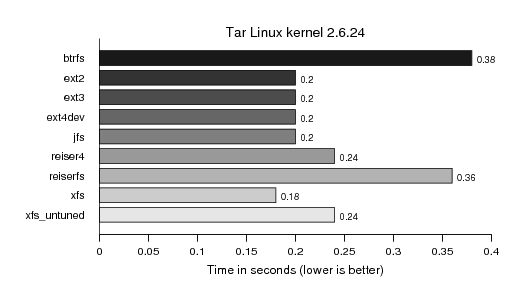
Re-readig the tree by creating a tar-ball (piped to /dev/null):
And again the cleanup (rm -rf). We already seen the XFS unlink performance above:
Finally, we apply a similar load using the T2 SDE source code, which consits of very many tiny (sub 4k) text description and patch files with the many additional .svn control (meta-data) files:
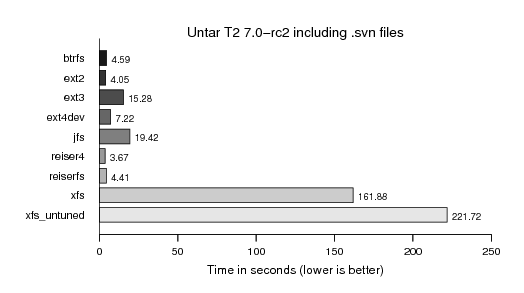
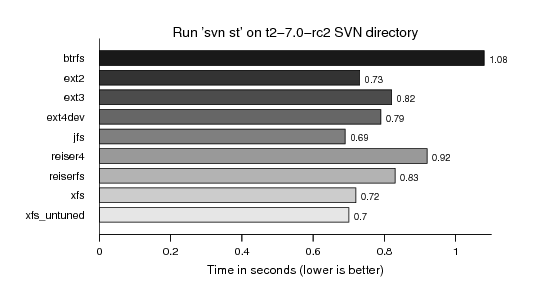
As I was particularly interested in the massiv i/o storm caused by svn operations (svn up, svn st) accessing and locking all the meta-data directories we measured a "svn st" run on the T2 tree. However, it did not differ as much as I estimated, probably because the data was still so hot, nicely sitting in caches:
Followed by creating yet again a tar-ball, however, this time writing it to the same disk, instead of /dev/null as with the previous kernel test:
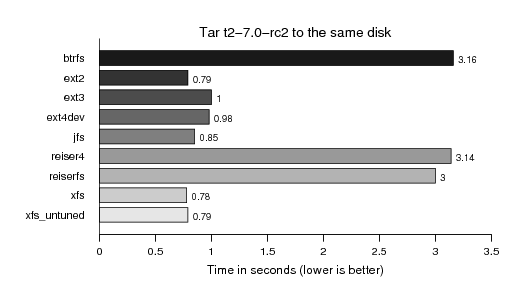
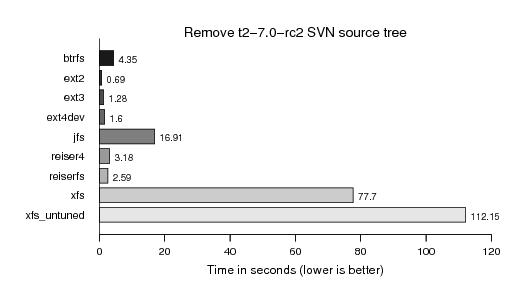
And finally also removing the T2 source tree, sniff:
Epilogue
I still like to avoid religious file-system flamewars I will again not attempt to promote a particular filesystem in this article.
However, still most noteably is the infamous XFS unlink performance, for which my tuning of two values at file system creation time did only help a little.
This raw data is for your further interpretation and for selection depending on your use case. This data is by no means complete.
It's also impressive how well JFS does perform, considering how few people dedicate their love maintaining it.
External links
The Author
René Rebe studied computer science and digital media science at the University of Applied Sciences of Berlin, Germany. He is the founder of the T2 Linux SDE, ExactImage, and contributer to various projects in the open source ecosystem for more than 20 years, now. He also founded the Berlin-based software company ExactCODE GmbH. A company dedicated to reliable software solutions that just work, every day.